리뷰 분석
1. 데이터 import 하기
- 데이터명(출처링크) : Women's E-Commerce Clothing Review
- 컬럼 정의 :
2. 테이블 정의
DESCRIBE mydata.dataset2;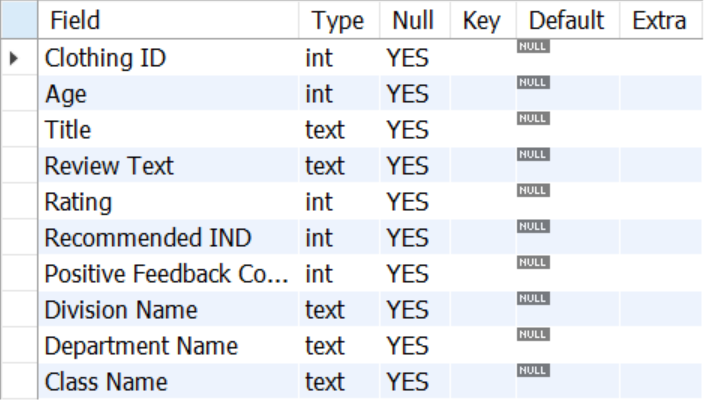
3. 분석 항목
I. 부서별 평점 분포
II. 주요 Complain
III. 연령별 평점 worst 부서
IV. SIZE Complain
V. 상품별 특정 문제에 대한 리뷰
I. 부서별 평점 분포
Q 1 . 어느 부서의 상품이 좋은 평가 혹은 나쁜 평가를 받았을까 ?
1 - 부서별 평균 평점 계산 (DIVISION NAME 기준)
SELECT `Division Name`,
AVG(rating) AVG_RATE
FROM mydata.dataset2
GROUP BY 1
ORDER BY 2 DESC;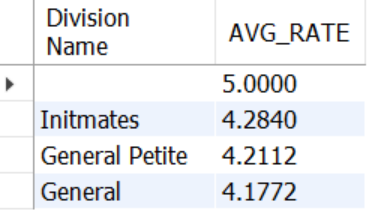
2- 부서별 평균 평점 계산 (DEPARTMENT NAME 기준)
SELECT `Department Name`,
AVG(rating) AVG_RATE
FROM mydata.dataset2
GROUP BY 1
ORDER BY 2 DESC;
3- 부서별 평균 평점 계산-Trend팀의 평점 3점 이하 리뷰
SELECT *
FROM mydata.dataset2
WHERE `Department Name` = 'Trend'
AND rating <= 3;
Q 1 .1 연령별 분포로 볼 수 있을까?
Trend 부서에 평점이 3점 이하인 리뷰의 연령대별 분포를 확인
SELECT CASE
WHEN age BETWEEN 0 AND 9 THEN '0009'
WHEN age BETWEEN 10 AND 19 THEN '1019'
WHEN age BETWEEN 20 AND 29 THEN '2029'
WHEN age BETWEEN 30 AND 39 THEN '3039'
WHEN age BETWEEN 40 AND 49 THEN '4049'
WHEN age BETWEEN 50 AND 59 THEN '5059'
WHEN age BETWEEN 60 AND 69 THEN '6069'
WHEN age BETWEEN 70 AND 79 THEN '7079'
WHEN age BETWEEN 80 AND 89 THEN '8089'
WHEN age BETWEEN 90 AND 99 THEN '9099'
END ageband,
age
FROM mydata.dataset2
WHERE `Department Name` = 'Trend'
AND rating <= 3;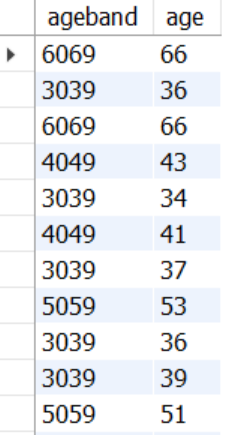
CASE문으로 추출한 연령별 분포에 FLOOR 함수를 적용
SELECT FLOOR(age/10)*10 ageband,
age
FROM mydata.dataset2
WHERE `Department Name` = 'Trend'
AND Rating <= 3;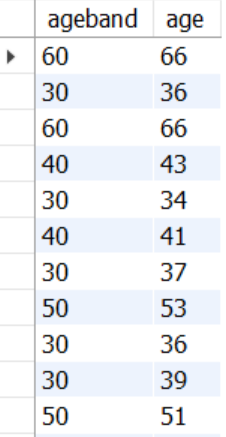
6 - Trend팀의 평점 3점 이하 리뷰의 연령별 분포
SELECT FLOOR(age/10)*10 ageband,
COUNT(*) cnt
FROM mydata.dataset2
WHERE `Department Name` = 'Trend'
AND Rating <= 3
GROUP BY 1
ORDER BY 2 DESC;
Q 1 .2 평점 낮은 리뷰가 많다고 가장 많은 불만이 있다고 할 수 있을까?
7-1. Trend팀의 전체 연령별 리뷰 수
SELECT FLOOR(age/10)*10 ageband,
COUNT(*) cnt
FROM mydata.dataset2
WHERE `Department Name` = 'Trend'
GROUP BY 1
ORDER BY 2 DESC;
7-2. Trend팀의 연령별 평점 낮은 리뷰 비중
SELECT FLOOR(age/10)*10 ageband,
CONCAT(ROUND((COUNT(CASE WHEN rating <= 3 THEN 1 END) / COUNT(*)) * 100, 2), '%') AS rating_ratio
FROM mydata.dataset2
GROUP BY 1
ORDER BY 2 DESC;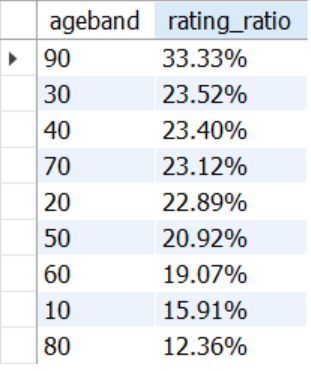
Trend팀의 평점 3점 이하인 리뷰들 중에서
평점 낮은 리뷰의 비율은 90대에서 33.33% 로 가장 높게 나타났고,
80대에서 12.36% 로 가장 낮게 나타났다.
* Trend부서의 연령별 평점(3점 이하)는 비율 기준이 되는 연령별 전체 리뷰수가 다 달랐다.
여기서 평점 낮은 리뷰의 비율을 연령대별로 비교하는 것이 적절한 비교인가?
Q 1 .3 주로 어떤 complain일까?
8 -1. 40대 3점 이하 Trend팀 리뷰 살펴보기
SELECT *
FROM mydata.dataset2
WHERE `Department Name` = 'Trend'
AND rating <= 3
AND age BETWEEN 40 AND 49
LIMIT 20;
8 -2. 50대 3점 이하 Trend팀 리뷰 살펴보기
SELECT *
FROM mydata.dataset2
WHERE `Department Name` = 'Trend'
AND rating <= 3
AND age BETWEEN 50 AND 59
LIMIT 20;II. 주요 Complain
Q 2. 부서별로 평점 낮은 주요 10개 상품의 리뷰 확인해볼까?
9 - 부서별 상품별 평균 평점 계산
SELECT `Department Name`,
`Clothing ID`, # Unique ID of the product
AVG(rating) avg_rate
FROM mydata.dataset2
GROUP BY 1, 2;
10 - 부서별 낮은 평점 순위 생성
SELECT *,
ROW_NUMBER() OVER (PARTITION BY `Department Name`
ORDER BY avg_rate) rnk
FROM (SELECT `Department Name`,
`Clothing ID`,
AVG(rating) avg_rate
FROM mydata.dataset2
GROUP BY 1, 2) A;
11 - 평점 낮은 1~10위 조회
SELECT *
FROM (SELECT *,
ROW_NUMBER() OVER (PARTITION BY `Department Name`
ORDER BY avg_rate) rnk
FROM (SELECT `Department Name`,
`Clothing ID`,
AVG(rating) avg_rate
FROM mydata.dataset2
GROUP BY 1, 2) A) B
WHERE rnk <= 10;
12 - [11] 결과로 stat 테이블 생성하기
CREATE TEMPORARY TABLE 테이블명 AS ()
CREATE TEMPORARY TABLE mydata.stat AS
SELECT *
FROM (SELECT *,
ROW_NUMBER() OVER (PARTITION BY `Department Name`
ORDER BY avg_rate) rnk
FROM (SELECT `Department Name`,
`Clothing ID`,
AVG(rating) avg_rate
FROM mydata.dataset2
GROUP BY 1, 2) A) B
WHERE rnk <= 10;
13 - 생성된 임시테이블로 상품 조회 : 부서이름-Dresses
SELECT `Clothing ID`
FROM mydata.stat
WHERE `Department Name` = 'Dresses';
14 - [13]결과에 해당하는 리뷰 내용 조회
SELECT *
FROM mydata.dataset2
WHERE `Clothing ID` IN (SELECT `Clothing ID`
FROM mydata.stat
WHERE `Department Name` = 'Dresses')
ORDER BY `Clothing ID`;III. 연령별 평점 worst 부서
Q 3. 리뷰 데이터 기반으로 worst 부서에 대한 프로모션(할인쿠폰)을 진행해볼까?
15 - 연령별 부서별 가장 낮은 점수 계산
SELECT `Department Name`,
FLOOR(age/10) * 10 ageband,
AVG(rating) avg_rating
FROM mydata.dataset2
WHERE rating IS NOT NULL
GROUP BY 1, 2;
16 - [15]결과 기반으로 순위 생성
SELECT *,
ROW_NUMBER() OVER (PARTITION BY ageband
ORDER BY avg_rating) rnk
FROM (SELECT `Department Name`,
FLOOR(age/10) * 10 ageband,
AVG(rating) avg_rating
FROM mydata.dataset2
GROUP BY 1, 2) A;
17 - [16]결과에서 1위 조회
SELECT *
FROM (SELECT *,
ROW_NUMBER() OVER(PARTITION BY ageband ORDER BY avg_rating) rnk
FROM (SELECT `Department Name`,
FLOOR(age/10)*10 ageband,
AVG(rating) avg_rating
FROM mydata.dataset2
GROUP BY 1, 2) A) B
WHERE rnk = 1;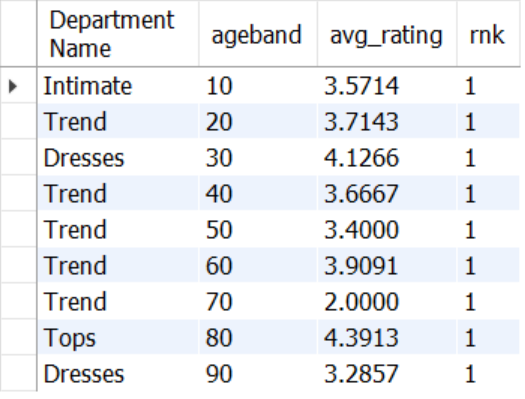
IV. SIZE Complain
Q 4. 특정 문제(ex.사이즈)에 대해서 살펴볼까? (ex. size complain)
18 - 'size'가 포함된 리뷰의 수
- 'size'란 단어를 포함하고 있는 리뷰 추출하기
SELECT `Review Text`,
CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END size_yn
FROM mydata.dataset2;
- 'size'란 단어를 포함하고 있는 리뷰수 추출하기
SELECT SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) n_size,
COUNT(*) n_total
FROM mydata.dataset2;
19 - 사이즈 상세 구분 리뷰의 수
SELECT SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) n_size,
SUM(CASE WHEN `Review Text` LIKE '%large%' THEN 1 ELSE 0 END) n_large,
SUM(CASE WHEN `Review Text` LIKE '%loose%' THEN 1 ELSE 0 END) n_loose,
SUM(CASE WHEN `Review Text` LIKE '%small%' THEN 1 ELSE 0 END) n_small,
SUM(CASE WHEN `Review Text` LIKE '%tight%' THEN 1 ELSE 0 END) n_tight,
SUM(1) n_total
FROM mydata.dataset2;
20 - 카테고리별로 사이즈 상세 구분 수치 확인
SELECT `Department Name`,
SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) n_size,
SUM(CASE WHEN `Review Text` LIKE '%large%' THEN 1 ELSE 0 END) n_large,
SUM(CASE WHEN `Review Text` LIKE '%loose%' THEN 1 ELSE 0 END) n_loose,
SUM(CASE WHEN `Review Text` LIKE '%small%' THEN 1 ELSE 0 END) n_small,
SUM(CASE WHEN `Review Text` LIKE '%tight%' THEN 1 ELSE 0 END) n_tight,
SUM(1) n_total
FROM mydata.dataset2
GROUP BY 1;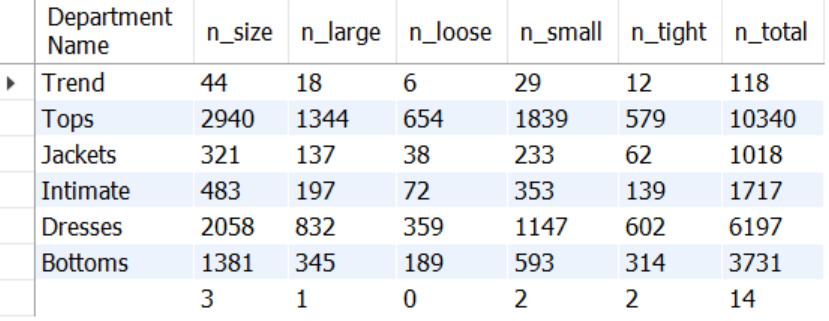
21 - 연령별 카테고리별 사이즈 상세 구분 수치 확인
SELECT FLOOR(age/10)*10 ageband,
`Department Name`,
SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) n_size,
SUM(CASE WHEN `Review Text` LIKE '%large%' THEN 1 ELSE 0 END) n_large,
SUM(CASE WHEN `Review Text` LIKE '%loose%' THEN 1 ELSE 0 END) n_loose,
SUM(CASE WHEN `Review Text` LIKE '%small%' THEN 1 ELSE 0 END) n_small,
SUM(CASE WHEN `Review Text` LIKE '%tight%' THEN 1 ELSE 0 END) n_tight,
SUM(1) n_total
FROM mydata.dataset2
GROUP BY 1, 2
ORDER BY 1, 2;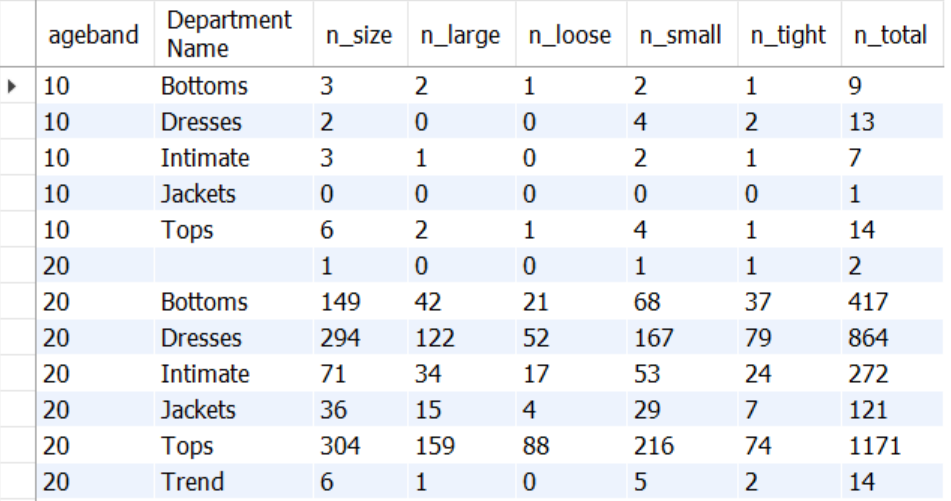
22 - 연령별 카테고리별 사이즈 상세 구분 비중 확인
SELECT FLOOR(age/10)*10 ageband,
`Department Name`,
SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) / SUM(1) ratio_size,
SUM(CASE WHEN `Review Text` LIKE '%large%' THEN 1 ELSE 0 END) / SUM(1) ratio_large,
SUM(CASE WHEN `Review Text` LIKE '%loose%' THEN 1 ELSE 0 END) / SUM(1) ratio_loose,
SUM(CASE WHEN `Review Text` LIKE '%small%' THEN 1 ELSE 0 END) / SUM(1) ratio_small,
SUM(CASE WHEN `Review Text` LIKE '%tight%' THEN 1 ELSE 0 END) / SUM(1) ratio_tight
FROM mydata.dataset2
GROUP BY 1, 2
ORDER BY 1, 2;V. 상품별 특정 문제에 대한 리뷰
Q 5. 특정 문제(ex.사이즈)가 있는 상품은 어떤 것일까?
23 - 상품별 사이즈 리뷰 수
SELECT `Clothing ID`,
SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) n_size
FROM mydata.dataset2
GROUP BY 1;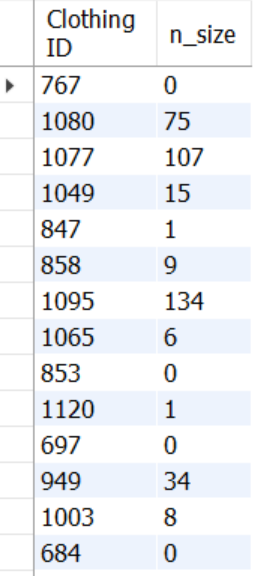
24 - 상품별 상세 사이즈별 리뷰수 비율
( %, 비율 소수점 둘째자리까지 반올림)
SELECT `Clothing ID`,
SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) n_size,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) / SUM(1))* 100, 2) ratio_size,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%large%' THEN 1 ELSE 0 END) / SUM(1)) * 100, 2) ratio_large,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%loose%' THEN 1 ELSE 0 END) / SUM(1)) * 100, 2) ratio_loose,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%small%' THEN 1 ELSE 0 END) / SUM(1)) * 100, 2) ratio_small,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%tight%' THEN 1 ELSE 0 END) / SUM(1)) * 100, 2) ratio_tight
FROM mydata.dataset2
GROUP BY 1;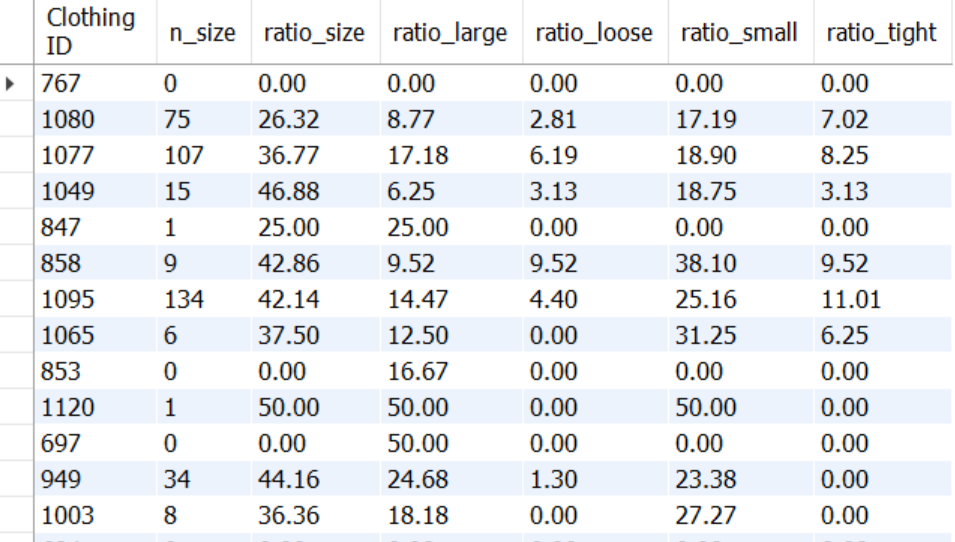
25 - 결과 테이블 생성하여 관련 부서(상품개발팀, 디자인팀 등)에 공유하기
CREATE TABLE mydata.size_stat AS
SELECT `Clothing ID`
,SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) n_size,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%size%' THEN 1 ELSE 0 END) / SUM(1))* 100, 2) ratio_size,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%large%' THEN 1 ELSE 0 END) / SUM(1)) * 100, 2) ratio_large,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%loose%' THEN 1 ELSE 0 END) / SUM(1)) * 100, 2) ratio_loose,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%small%' THEN 1 ELSE 0 END) / SUM(1)) * 100, 2) ratio_small,
ROUND((SUM(CASE WHEN `Review Text` LIKE '%tight%' THEN 1 ELSE 0 END) / SUM(1)) * 100, 2) ratio_tight
FROM mydata.dataset2
GROUP BY 1;'Data analysis > SQL +' 카테고리의 다른 글
| 모바일 앱 분석을 위한 지표 13 (0) | 2023.03.29 |
|---|---|
| [MySQL] 매출 데이터 분석 : 구매지표 - 베스트셀러 (0) | 2022.08.15 |
| [MySQL] 매출 데이터 분석 : 구매지표 - 재구매율 (0) | 2022.08.15 |
| [MySQL] 매출 데이터 분석 : 구매지표II - ABC분석(매출 중요도 등급) (0) | 2022.08.15 |
| [MySQL] 매출 데이터 분석 : 구매지표 - 그룹별 구매지표 (0) | 2022.08.15 |