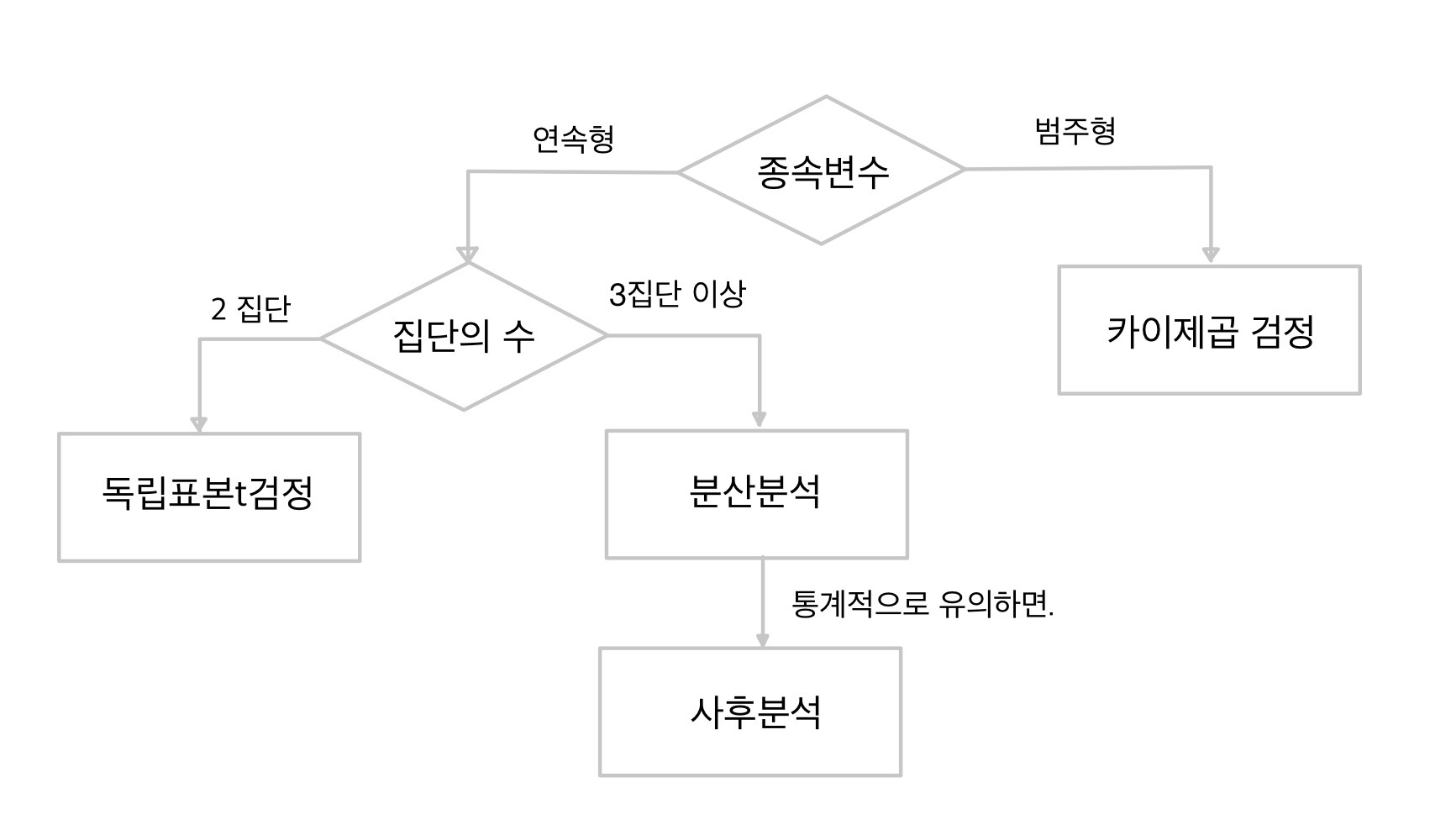
집단분석 [1단계] 데이터 불러오기 # 데이터셋 불러오기 import pandas as pd dp = pd.read_excel('c:\\data\\depression.xlsx') dp.head() dp.head() dp.info() y : 치료효과 [2단계] 집단의 등분산성 비교하기 levene 검정 · 귀무가설 : 분산이 같다. import pingouin as pg pg.homoscedasticity(dv='y', group='TRT', data=dp) > 결과 : pval가 0.000416 으로 0.05 보다 작다. 분산이 같다는 귀무가설을 기각하고, 등분산성을 만족하지 않는 것으로 보고 진행한다. 집단 분석에서 등분산성을 만족하지 않을 때 > welch_anova [3단계] 분산분석 · 귀무가설 ..