텍스트 분석 : 자연어
KEYWORD
자연어
문서단어행렬
자연어 Natural Language
자연어 natural language
: 한국어, 영어 등 자연스럽게 생겨난 언어
인공어 constructed language
- 에스페란토(1887): 자멘호프가 국제적 의사소통을 위해 개발
- 나비 : 영화 아바타의 외계인 언어로 사용하기 위해 개발
통제 자연어 controlled natural language
형식어 formal language
: 수식, 프로그래밍 언어 등
자연어 특징
• 규칙이 복잡하고, 예외가 많음
• 음운론, 통사론, 의미론 등 다양한 수준으로 이뤄져 있음
| 종 류 | 설 명 | 예 |
| 음소 phoneme | - 언어에서 소리의 가장 작은 단위, 그 자체로는 의미없음 | |
| 형태소 morpheme | - 의미가 가장 작은 단위 | multi- |
| 단어 word | - 독립적으로 쓰일 수 있는 형태소 | media |
| 구문 구조 syntax | - 단어들이 모여서 문장을 이루는 구조 해석을 위해서는 여러 수준에 대한 복합적인 고려가 필요함 |
Time flies like an arrow; fruit flies like a banana. |
자연어 처리 접근 방식
| 규칙 기반 rule-based | 머신러닝 Machine learning |
|
• 언어의 규칙을 프로그래밍
• 단순한 처리는 쉽게 가능
• 다양한 예외, 모호성 등으로 복잡한 처리는 어려움
|
• 방대한 데이터를 바탕으로 패턴을 추출
• 복잡한 처리도 가능
• 데이터를 손으로 분류하는 비용이 높음
|
문서 단어 행렬 Documetn Term Maxtirx
> 문서별로 단어 빈도를 정리한 표
문서 단어 행렬의 장단점
| 장점 | 단점 |
| • 비정형 데이터인 텍스트를 표 형태로 정형화 • 정형 데이터의 다양한 통계 기법을 적용 가능 |
• 처리가 단순 ↔ 어순과 맥락을 무시 |
CountVectorizer 실습
① 데이터 임포트하기
import pandas as pd
df = pd.read_excel('yelp.xlsx')
df.head()> 데이터 확인
df.head()
df.tail()
df.shape # 데이터 형태
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_features = , stop_words = 'english')
|
# 문서 단어 행렬 설정
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_features=500, stop_words='english')
> 영어 불용어 목록 보기 와 추가하기
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDSENLISH_STOP_WORDS # 불용어 목록stop_words = ENGLISH_STOP_WORDS | {'추가하고싶은단어'} # 단어 추가
실습
< review 컬럼으로 문서 단어 행렬 만들기 >
# df의 review 컬럼을 바탕으로 문서 단어 행렬을 만든다.
import pandas as pd
df = pd.read_excel('yelp.xlsx')
df.columns # Index(['review', 'sentiment'], dtype='object')
# 문서 단어 행렬 설정
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_features=500, stop_words='english')
# df의 review 컬럼으로 문서 단어 행렬을 만든다.
dtm = cv.fit_transform(df['review'])
# 형태 확인
dtm.shape # (1000, 500)
# 단어 목록을 확인
# 단어 목록은 dtm이 아닌 cv에 저장된다.
cv.get_feature_names()
> dtm
<1000x500 sparse matrix of type '<class 'numpy.int64'>'
with 3393 stored elements in Compressed Sparse Row format>
> 압축을 풀어서 보려면 .A
dtm.A
> ★ 단어별 총 빈도 .sum(axis=0)
dtm.sum(axis=0)
> 단어별 빈도수가 출력됨.
> ★ 문서별 총 단어수 .sum(axis=1)
> 단어 빈도 데이터 프레임 만들기
word_count = pd.DataFrame({'단어':cv.get_feature_names(),
'빈도': dtm.sum(axis=0).flat
})
word_count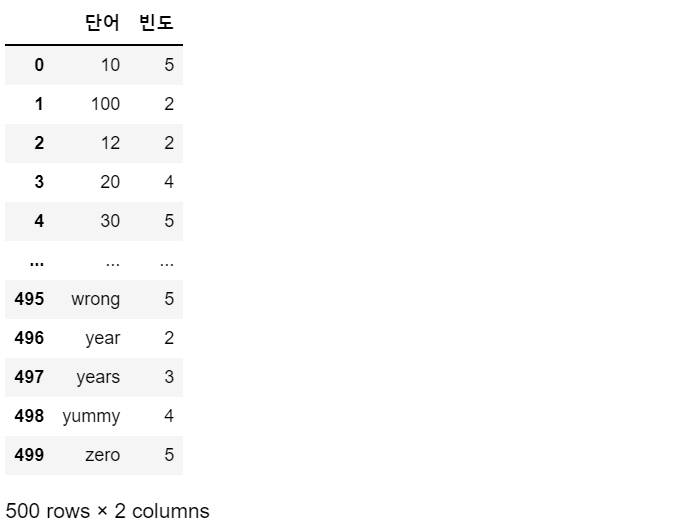
> 필요 항목에 따라 정렬 가능
.sort_values('빈도', ascending=False)

'기초통계' 카테고리의 다른 글
| 표본추출분포 (0) | 2023.09.04 |
|---|---|
| [텍스트 분석] 희소행렬 (0) | 2022.10.11 |
| [차원축소와 군집분석] 군집분석 : Clustering (0) | 2022.10.04 |
| [기초통계] 차원 축소와 군집 분석 (0) | 2022.09.15 |
| 상호작용과 인과 : 횡단 비교와 종단 비교 (0) | 2022.09.13 |