로지스틱 회귀분석
KEYWORD
일반화 선형모형
로지스틱 함수
승산
한계효과
로그우도
이탈도
유사 R제곱
일반화 선형모형 Generalized Linear Model
다양한 종속변수를 분석할 수 있도록 선형 모형을 확장한 것
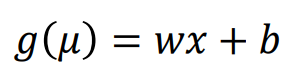
• 𝜇(뮤) : 종속 변수의 기댓값
• 𝑔 : 연결 함수 link function
로지스틱 함수 logistic function
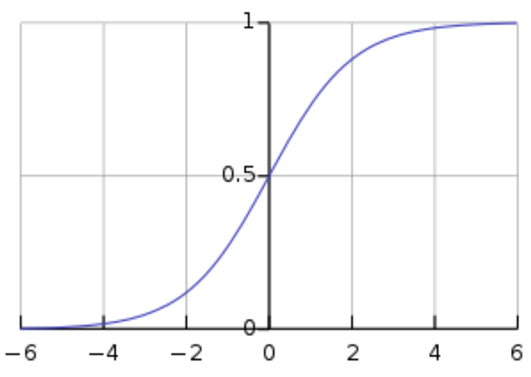
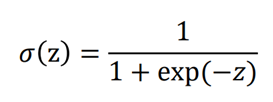
0 ~ 1 사이의 출력을 갖는 함수
'확률'은 0~1 사이의 값이므로 확률을 출력하는 함수를 만들 수 있다.
연습
import pandas as pd
ch = pd.read_excel('churn.xlsx')
ch.head()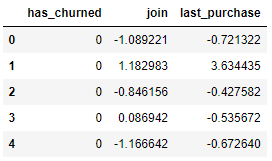
- has_churned : 고객이 이탈을 했는가 (0 유지, 1이탈)
- join : 가입기간 (표준화된 상태) 0이 평균적인 가입기간
- last_purchase : 마지막 구매 후 기간(표준화된 상태)
from statsmodels.formula.api import logit
logit('y ~ x', data).fit().summary()
① 가입기간(join)으로만 예측
from statsmodels.formula.api import logit
m = logit('has_churned ~ join', ch).fit()
m.summary()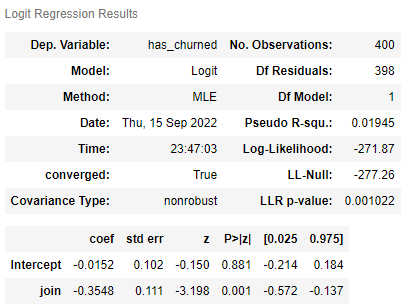
·
· join 의 coef : (-)
> join이 길어지면 이탈할 확률이 줄어든다.
· 선형 회귀
-0.0152 - 0.3548 * join
> 로지스틱 회귀
from scipy.special import expit
expit(logit 분석 모델)
| # 로지스틱 회귀의 경우, 계산 | # 전체 고객에 대한 이탈률을 구하려면 | # 실제 고객 이탈 여부와 비교 |
| from scipy.special import expit expit(-0.0152 + (-0.3548 * -1.089221)) |
m = logit('has_churned ~ join', ch).fit() # m.summary() m.predict(ch) |
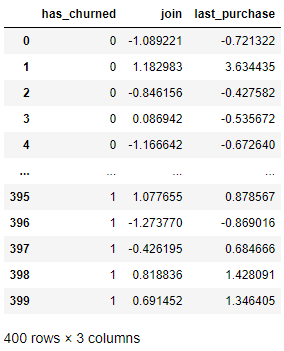
ch |
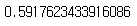 |
 |
 |
② 가입기간(join)과 구매일자(purchase)로 예측
from statsmodels.formula.api import logit
m2 = logit('has_churned ~ join + last_purchase', ch).fit()
m2.summary()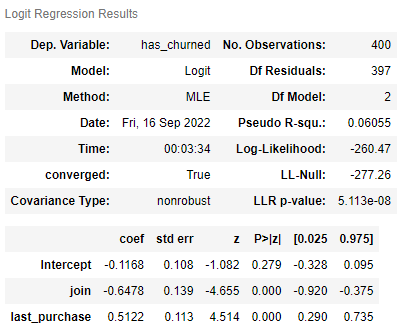
· last_purchase 의 coef : (+)
> 마지막 구매 후 기간이 길어지면 고객이 이탈할 확률이 증가한다.
> 기울기로 비교해보면 join이 last_purchase보다 절대적인 기울기가 더 크다. 따라서 고객의 이탈에 join이 last_purchase보다 더 큰 영향을 끼친다고 말할 수 있다.
| # 전체 고객에 대한 이탈률을 구하려면 | |
| m2 = logit('has_churned ~ join + last_purchase', ch).fit() # m2.summary() m2.predict(ch) |
 |
승산
| 양성의 확률 / 음성의 확률 | 로짓(logit) : 로그 승산 |
 |
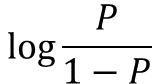 |
한계효과
x의 추가 변화에 따른 y의 추가 변화
• 로지스틱 회귀분석에서 로짓의 한계 효과는 일정, 확률의 한계효과는 x 에 따라 다름
• 선형 모형에서는 한계 효과가 x의 기울기 w로 일정
• 𝑤𝑥 + 𝑏 = 0일 때 한계효과가 가장 큼
로지스틱 회귀분석의 적합도 지수
로그우도
이탈도(Deviance) = -2 x 로그우도
AIC
BIC
우도 Likelihood
특정한 추정치에서 관찰된 데이터가 나올 확률
즉, 실현된 쪽
예) 동전을 던져서 앞뒤뒤가 나왔을 경우(관찰된 데이터)
전체 데이터의 우도를 계산하려면 모든 우도를 곱하면 된다.
문제1) 숫자가 너무 작아져서 컴퓨터로 계산이 어려움
문제2) 숫자가 너무 작아서 불편함.
🧵 곱셈을 한 다음에 로그를 씌운다 = 로그(log)를 씌워서 덧셈으로 바꾼다.
장점1) 곱셈보단 덧셈이 쉽지
장점2) 로그는 숫자가 별로 커지거나 작아지지 않는다.
∴ 그냥 우도보다 로그 우도(Log-Likelihood)를 사용한다.
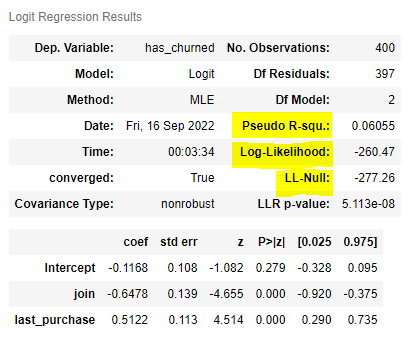
· LL-Null
> 모든 고객이 같은 확률로 예측
(이탈 확률이 똑같다고 보는것.)
ch.has_churned.mean()
전체 고객의 이탈 평균 0.5
> 로그 우도가 -260.47로 LL-Null보다 조금 더 높다. 즉, 예측을 좀더 잘 했다고 볼 수 있다.
그럼 얼마나 잘했나? 그걸 나타내는 것이 Psedo R-squ (유사 R제곱)
● LL-Null
: 모든 확률이 50%라고 예측한 로그우도
# LL-null 모든 고객의 이탈확률이 50%라고 예측한 후 로그우도 계산
import numpy as np
400 * np.log(0.5)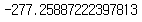
> 로지스틱 회귀에서 구한 LL-Null값과 동일하다.
McFadden의 유사 R제곱
선형 회귀분석의 R제곱과 비슷하게 해석할 수 있도록 만든 값
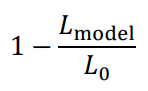
• 𝐿model: 분석 모형의 로그 우도
• 𝐿0 : 독립변수 없이 예측할 때의 로그우도 ← LL-Null
- 로지스틱 회귀분석에서는 교차검증 하지 않을거라면 AIC와 BIC로 보면 된다.
📌
수치(예:가격) -> 선형 회귀분석
확률(예:탈퇴) -> 로지스틱 회귀분석
: 코로나 확진이냐 아니냐 : 암이다, 아니다 : (고객) 탈퇴다. 유지다 : (고객) 가입할것인가, 안할 것인가
즉, 범주형(둘중 하나)에 쓰인다.
Q. 로지스틱 회귀분석은 로지스틱 함수의 모양이 '비선형'일 뿐 범주의 확률이니 선형/ 비선형은 크게 중요하지 않을건가?
> 비선형적인 것은 중요하다.
확률이 일정하게 떨어지는 것이 아니고 50% 근처에서는 많이 변하고 0% 와 100% 근처에서는 작게 변한다.
예) churn 데이터에서 가입기간을 계산
| from scipy.special import expit join = 0 last_purchase = 0 expit(-0.1168 + -0.6478 * join + 0.5122 * last_purchase) |
> 이탈확률 감소치가 점점 감소한다. |
|
| > 둘다 평균정보면 이탈 확률 > 47 % join=0, 표준편차 더 길어지면 이탈확률 31% (-16%) join=2, 표준편차 더 길어지면 이탈확률 19% (-12%) join=3,이 3 표준편차 더 길어지면 이탈확률 11% (-8 %) |
||
Q. expit?
> 확률이 어떻게 올라가고 내려가는지 보여줄 수 있는 함수임.
실제로 예측할 때는 모델.predict() 사용하면 된다.
Python 예측
| 단계 | 코드 | 결과 |
| 만든 모델로 확률 예측하기 |
prob = m2.predict(ch) prob |
 |
| 문턱값보다 크면 1 아니면 0 으로 예측 |
import numpy as np pred = np.where(prob > 0.5, 1, 0) pred |
 |
| 혼동행렬로 확인하기 (정답과 예상치 비교) |
from sklearn.metrics import confusion_matrix confusion_matrix(ch.has_churned, pred) |
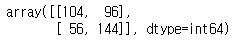  |
* m2 : 가입일자(join)과 최근 구매일자(last_purchase)로 예측한 모델
'기초통계' 카테고리의 다른 글
| 로지스틱회귀분석 : 혼동행렬, ROC_Curve (0) | 2022.09.13 |
|---|---|
| [실습] 회귀분석 : birthsmokers data (0) | 2022.09.10 |
| 다중회귀분석 : 변수의 변형 (로그함수, I 함수, 2차항의 추가, 절편) (0) | 2022.09.06 |
| 다중회귀분석 : 단계적 회귀분석 (0) | 2022.09.06 |
| 다중회귀분석 : 교차검증 (0) | 2022.09.06 |