로지스틱 회귀분석 : 혼동행렬
KEYWORD
혼동행렬 (Confusion-Matrix)
정확도 (Accuracy)
정밀도 (Precision)
재현도 (Recall)
특이도 (Specision)
F1 - score
ROC Curve
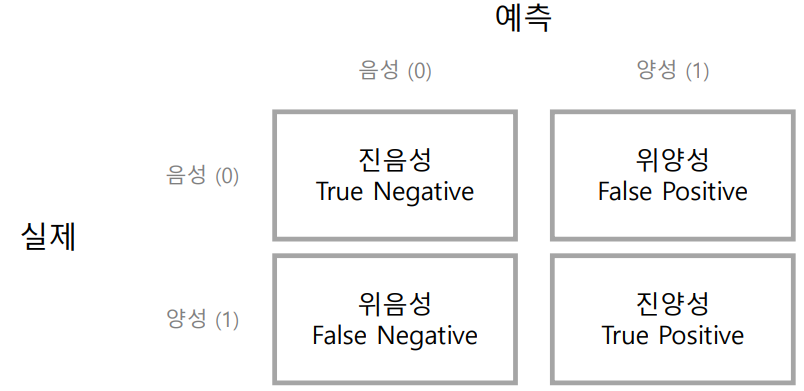
혼동행렬 confusion matrix
Python 에서의 혼동행렬
from statsmodels.formula.api import logit
from sklearn.metrics import confusion_matrix
m = logit('y ~ x1 + x2', df).fit()
m.summary()
# 로지스틱 회귀분석
import pandas as pd
df = pd.read_excel('churn.xlsx')
from statsmodels.formula.api import logit
m = logit('has_churned ~ join + last_purchase', df).fit()
m.summary()
# 종속변수에 들어가는 값은 0,1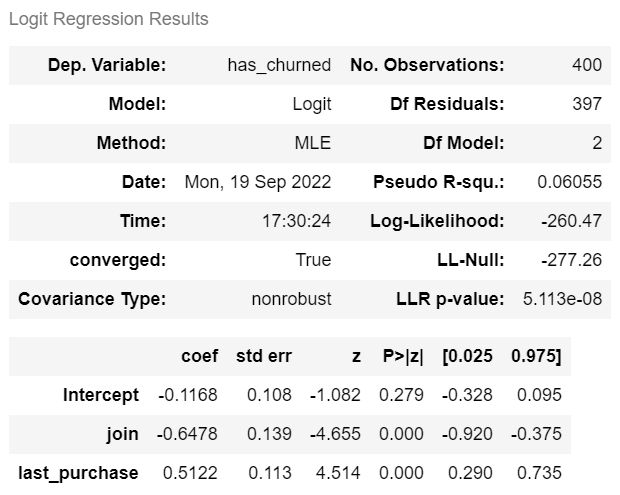
> 예측하기
import numpy as np
prob(예측값) = m.predict(df)
y_pred = np.where(prob > 0.5, 1, 0)
# 확률 예측하기
import numpy as np
prob = m.predict(df)
y_pred = np.where(prob > 0.5, 1, 0) # has_churned에 대한 예측값
y_pred
> 혼동행렬 구하기
# 혼동행렬
# confusion_matrix(y, y_pred)
from sklearn.metrics import confusion_matrix
confusion_matrix(df.has_churned, y_pred)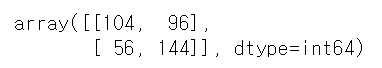
우리의 예측이 어떻게 맞고 틀리는지 확인할 수 있다.
진/위 양성/음성
혼동행렬에서 양성/음성은 예측을 기준으로 말함
현실에서는 실제로 어떤지 알 수 없는 경우가 많음
• 진(True) → 예측이 맞음
• 위(False) → 예측이 틀림

정확도 Accuracy
전체 중에 예측이 맞은 비율
(TP + TN) / 전체
특별히 음성/양성 구분에 관심이 없는 경우에 사용
(대부분은 양성에 더 관심이 있음)
Python 에서의 정확도
from sklearn.metrics import *
accuracy_score( 실제값, 예측값 )
# 정확도 Accuracy
from sklearn.metrics import *
accuracy_score(df.has_churned, y_pred)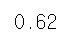
그러나 우리는 보통 '양성'에 더 관심이 많다.
그럴 때 확인할 수 있는 것 = ' 정밀도(Precision) '
정밀도 Precision
양성 예측 중에 맞은 비율
TP / (TP + FP)
양성 예측이 중요한 경우 > 예: 채용
● 동일한 분석일 때 정밀도를 높이고 싶다면?
> 대체로 문턱값을 높이면(보수적 예측) 정밀도가 높아진다.
Python 에서의 정밀도
from sklearn.metrics import *
precision_score( 실제값, 예측값 )
# 정밀도 Precision
from sklearn.metrics import *
precision_score(df.has_churned, y_pred)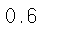
재현도 recall
실제 양성 중 찾아낸 비율
TP / (TP + F N)
• 양성을 찾아 내는 것이 중요한 경우 (예: 방역)
• 의학 등에서는 민감도(specificity)라고도 함
• 대체로 문턱값을 낮추면(적극적 예측) 재현도가 높아진다.
예) 코로나 선별 검사 PCR 검사
판정 '양성' 실제 '음성' > 위양성(FP)
판정 '양성' 실제 '양성' > 진양성(TP)
판정 '음성' 실제 '음성' > 진음성(TN)
판정 '음성' 실제 '양성' > 위음성(FN)
특이도 Specificity
실제 음성 중 찾아낸 비율
TN / ( TN + FP )
• 음성을 찾아 내는 것이 중요한 경우
예: 방역
• 대체로 양성 예측을 보수적으로 하면 특이도가 높아진다
'이탈고객 예측' 은
· 재현도가 중요하다(떠날 사람들을 빨리 찾아서 붙잡아야 하니까)
예) 코로나 걸린 사람들은 빨리 찾아내야 확산을 줄일 수 있다.
· 정밀도도 중요할 수 있다.(떠날 것으로 예상되는 사람들에게 비용이 큰 프로모션을 할 경우, 정밀도가 높아야 비용을 효율적으로 쓸 수 있다.)
예) 리텐션을 유지하기 위해 비용을 투자한 사람중에 실제로 남은 사람이 많아야 투자 비용 대비 효과가 높은거니까
· 정확도는 대부분 중요하다고 보기 어려울 것이다. 왜냐하면 대부분 고객이 유지고객일 것이므로.
무조건 어떤 지표가 중요하다고 할 수는 없고,
상황에 따라서 가장 설득력 있는 적절한 지표 를 생각해 낼 수 있을 것.
F1
정밀도(p)와 재현도(r)의 조화 평균
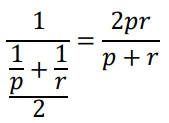
• 조화평균 : 역수의 평균의 역수
• 비율, 속도 등을 평균낼 때는 산술평균 대신 조화평균을 사용.
📌 조화평균을 사용하는 이유?
예) 서울에서 부산까지 가는데 서울- 부산까지 거리가 400km 하자.
갈 때는 시속 200km, 올때는 시속 100km
걸린시간은 갈 때 2시간, 올 때 4시간
따라서 평균속도는 800km / 6hr = 166km/hr
시속의 산술평균으로 구하면 150km/hr
* 산술평균은 더하기 (p+r/2)이므로 하나가 높고 다른 하나가 낮아도 티가 나지 않지만
조화 평균은 둘중 하나가 낮으면 수치가 급격히 낮아진다.
# F1 조화평균 구하기
from sklearn.metrics import *
f1_score(df.has_churned, y_pred)f1-score은 정밀도와 재현율이 둘다 높으면 높다.
그러나 정밀도와 재현율을 둘다 높이는 것은 쉽지 않다.
'정밀도'는 문턱을 높여야 높아지고,
'재현율'은 문턱을 낮춰야 높아지므로 둘다 높이는 것은 분석을 매우 잘했다는 것.
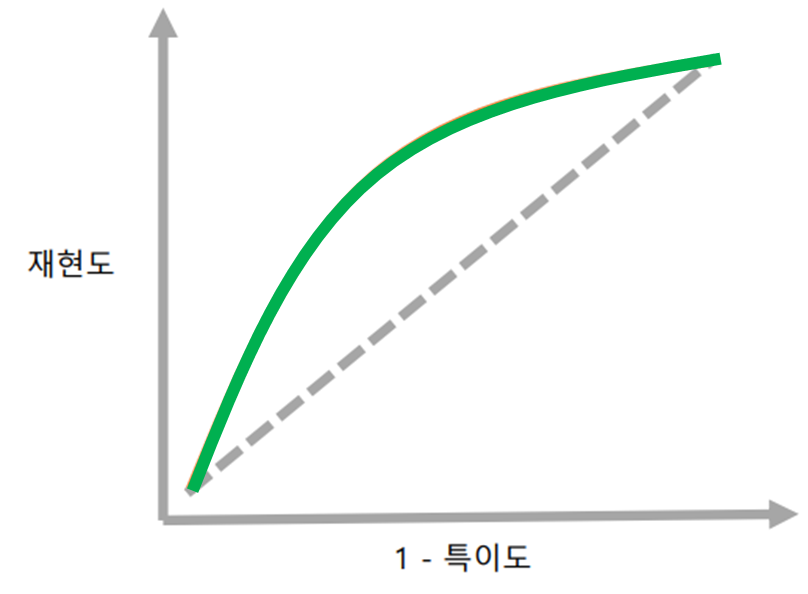
ROC 곡선
Receiver operating characteristic
• 신호 이론에서 유래
• 가로축은 (1-특이도), 세로축은 재현도
• 문턱값을 변화시키면서 특이도와 재현도의 변화를 곡선으로 표시
 |
 |
 |
문턱을 낮추면, 재현율 ▲, 특이도와 정밀도 ▼
문턱을 높이면, 재현율 ▼, 특이도와 정밀도 ▲
곡선하 면적 Area Under the Curve
ROC 곡선 아래의 면적 (약칭 AUC)
• 0~1 범위
• 무작위로 예측할 경우 0.5
• 1에 가까울 수록 성능이 높음.
Python 에서의 ROC 커브
import pandas as pd
threshold = [] # 문턱값
precision = [] # 정밀도
recall = [] # 재현도
for i in range(1, 9, 1):
y_pred = np.where(prob > 0.1 *i, 1, 0) # has_churned에 대한 예측값
p = precision_score(df.has_churned, y_pred)
r = recall_score(df.has_churned, y_pred)
threshold.append(i)
precision.append(p)
recall.append(r)
roc_curve = pd.DataFrame()
roc_curve['thresholdx10'] = threshold
roc_curve['p'] = precision
roc_curve['r'] = recall
roc_curve['1-p'] = roc_curve['p'].apply(lambda x : 1-x)
roc_curve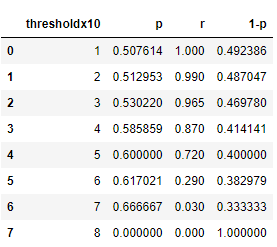
import sklearn.metrics import roc_curve_score, roc_curve
import matplotlib.pyplot as plt
# 거짓긍정률, 참긍정률, 문턱값
fpr, tpr, threshold = roc_curve(실제값, 예측값)
plt.plot(fpr, tpr)
roc_curve_score(예측값, 실제값)
# ROC 커브
from sklearn.metrics import roc_auc_score, roc_curve
import matplotlib.pyplot as plt
# 거짓긍정률, 참긍정률, 문턱값
fpr, tpr, threshold = roc_curve(df.has_churned, y_pred)
plt.plot(fpr, tpr)
roc_auc_score(df.has_churned, y_pred)· 정밀도 = 양성으로 예측한 것중에 실제 양성
· 특이도 = 실제 음성중에 음성 판정
둘다 문턱값을 높이면 높아지는 공통점이 있다.
'재현도(recall)'은 문턱값을 높이면 낮아진다.
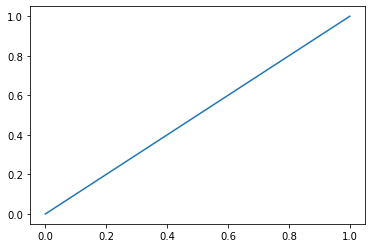
ROC curve 왜 그리나?
문턱값(threshold)에 따라서 지표들이 바뀌게 된다.
문턱값을 올리거나 내리면, 어떤 지표는 좋아지지만 다른 지표는 나빠진다.
대표적인 예) 재현도 vs 특이도
특이도에서 얼마만큼 좋아지면, 재현도가 얼마나 나빠지는가를 시각화하는게 목적
특이도가 많이 좋아지는데 재현도가 별로 안나빠진다면 Good
특이도가 많이 좋아지는데 재현도도 많이 나빠진다 Bad
예) 회사에서의 광고비
광고비 많이 쓰면? 매출은 증가, 그러나 비용이 증가하므로 이익이 감소
광고비 적게 쓰면? 매출은 감소, 이익은 증가
'기초통계' 카테고리의 다른 글
| 상호작용과 인과 : 인과효과 (0) | 2022.09.13 |
|---|---|
| 상호작용과 인과 : 상호작용 (0) | 2022.09.13 |
| [실습] 회귀분석 : birthsmokers data (0) | 2022.09.10 |
| 로지스틱 회귀분석 (0) | 2022.09.06 |
| 다중회귀분석 : 변수의 변형 (로그함수, I 함수, 2차항의 추가, 절편) (0) | 2022.09.06 |