다중회귀분석 : 교차검증
교차검증
수정R제곱, AIC, BIC 등은 이론적 보정이므로 과적합을 정확히 반영하지 못한다.
그래서 데이터가 충분히 많다면, 데이터를 여러 개의 셋으로 나누어 교차 검증을 한다.
• 한 데이터셋의 분석 결과를 다른 데이터셋에 적용하여 예측 오차를 확인 (예측 오차가 적은 모형이 좋은 모형)
• 이론적 가정에 의존하지 않으므로 데이터가 충분히 많을 때는 교차 검증을 권장
KEYWORD
교차검증 종류
교차검증 결과
Python에서의 교차검증
교차검증 종류
데이터를 훈련 데이터와 테스트 데이터로 분할
모형을 훈련 데이터에 적합시켜, 테스트 데이터를 예측
| 검증 종류 | 방법 |
| LpOCV (Leave-p-out) | : p개를 제외한 모든 사례로 추정에 사용. p개는 가능한 모든 방법으로 조합. 조합이 지나치게 많아서 비현실적이므로 잘 사용하지 않음. |
| LOOCV (Leave-one-out) | : p = 1인 경우. 데이터가 N개이면 N번 검증 이것도 분석을 많이 해야하지만 프로그래밍으로 하면 금방 할 수 있음. |
| K-fold | : 데이터를 크게 k개의 셋으로 나눔. 한 셋 씩 테스트셋으로 사용. k번 교차검증 |
| holdout | : 데이터를 훈련 셋과 테스트 셋으로 한 번만 나누어 1회 교차 검증 |
교차검증 결과
| 훈련 오차 ▲ , 테스트 오차 ▲ | 훈련오차 ▼ , 테스트 오차 ▼ | 훈련 오차 ▼, 테스트 오차 ▲ |
| - 과소적합 - 모형을 더 복잡하게 수정 필요 |
👍🏻 | - 과대적합 - 모형을 더 단순하게 수정 |
Python에서 교차검증
from sklearn.model_selection import train_test_split
train, test = train_test_split(data, tests_size=0.2, random_state=42)
import pandas as pd
df = pd.read_excel('car.xlsx')
# 데이터 분할
from sklearn.model_selection import train_test_split
train_df, test_df = train_test_split(df, test_size = 0.2, random_state=42)df < 원자료
test_size < 테스트 데이터의 비율 설정
random_state < 난수 생성의 seed들을 고정(동일한 분할을 하기 위함)
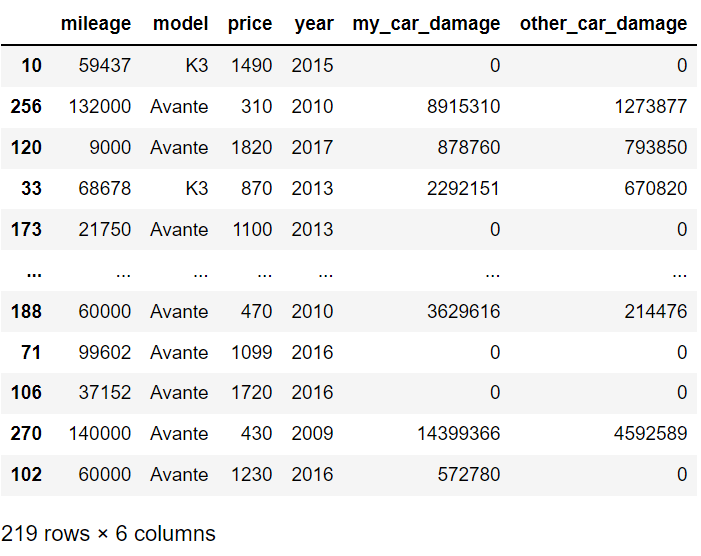
데이터 분석
: 독립변수 > year + mileage
# 데이터 분석
from statsmodels.formula.api import ols
m = ols('price ~ year + mileage', train_df).fit()예측
m.predict(테스트데이터)
# 예측
y_test = m.predict(test_df)
y_test
# 실제 팔린 가격
test_df.price
잔차분산
from sklearn.metrics import mean_squared_error
mean_squared_error(예측값, 테스트정답)
# 잔차분산
from sklearn.metrics import mean_squared_error
# 연식(year)과 주행거리(mileage)로 예측했을 때의 오차
mean_squared_error(test_df.price, y_test)
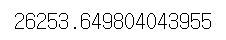
# 평균으로 예측할 때의 오차
test_df.price.var()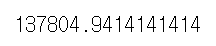
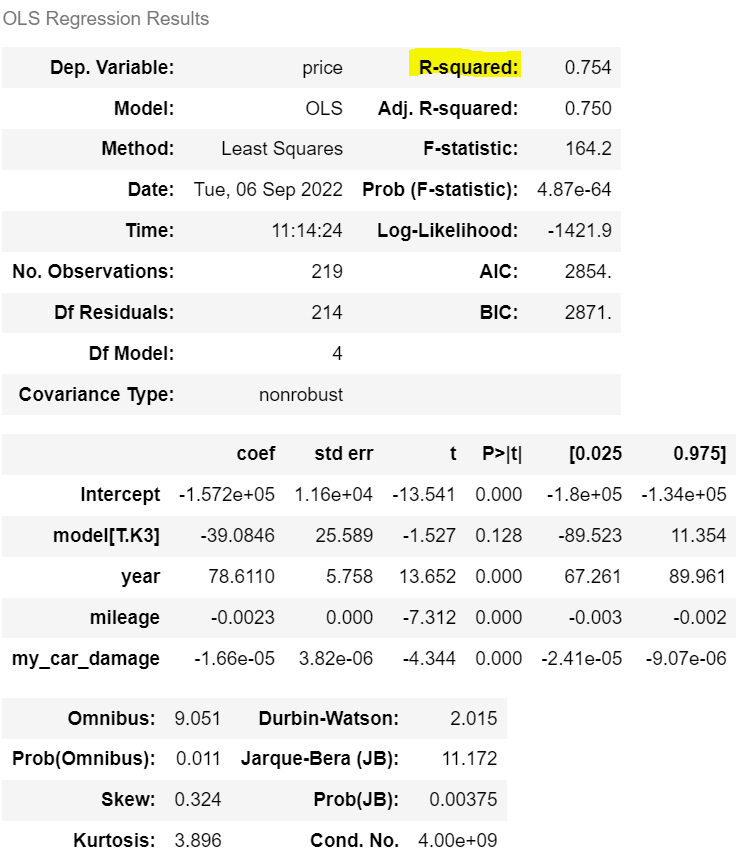
m.summary()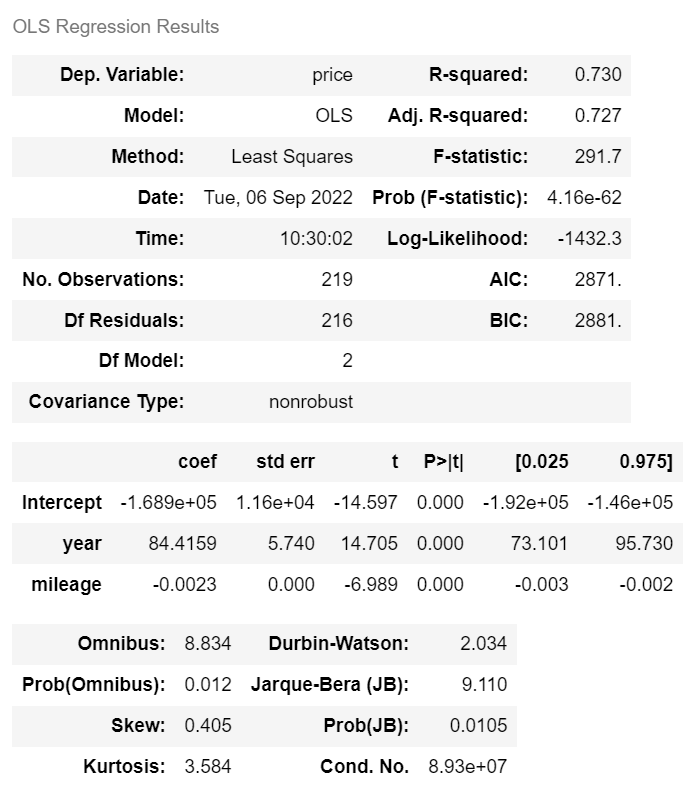
ols 는 쓸데없는 변수를 넣어도 R² 값이 올라간다.
데이터 분석 > 독립변수 추가
| 독립변수 > year + mileage + model |
독립변수 > year + mileage + model + my_car_damage |
| # 예측 | # 예측 |
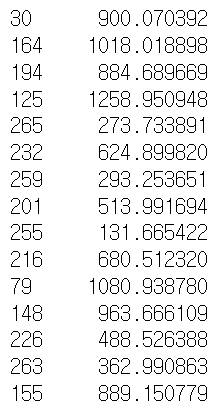
| m3 = ols('price ~ year + mileage + model', train_df) .fit() y_test3 = m3.predict(test_df) y_test3 |
m4 = ols('price ~ year + mileage + model + my_car_damage', train_df).fit() y_test4 = m4.predict(test_df) y_test4 |
 |
 |
| # 잔차분산 | # 잔차분산 |
| # 연식(year)과 주행거리(mileage)로 예측했을 때의 오차 from sklearn.metrics import mean_squared_error mean_squared_error(test_df.price, y_test3) |
# 연식(year)과 주행거리(mileage), 차종(model), 자차 손해(my_car_damage)로 예측했을 때의 오차 from sklearn.metrics import mean_squared_error mean_squared_error(test_df.price, y_test4) |
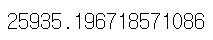 |
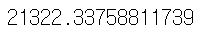 |
| # Rsquared | # Rsquared |
| 0.733 |
0.754 |
 |
 |
· 모든 예측을 평균으로 했을 때 mse는 분산과 같다.
# 모든 예측을 평균으로 했을 때 mse(Mean Squared Error)는 분산과 같다.
import numpy as np
y_test = np.tile(test_df.price.mean(), 55) # 모든 예측을 평균
mean_squared_error(test_df.price, y_test)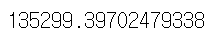
test_df.price.var(ddof=0)
'기초통계' 카테고리의 다른 글
| 다중회귀분석 : 변수의 변형 (로그함수, I 함수, 2차항의 추가, 절편) (0) | 2022.09.06 |
|---|---|
| 다중회귀분석 : 단계적 회귀분석 (0) | 2022.09.06 |
| 회귀분석 : 다중회귀분석 (0) | 2022.09.05 |
| 상관과 회귀 : 회귀분석 (0) | 2022.09.05 |
| [실습] 집단분석 : Depression.xlsx 데이터 (0) | 2022.08.25 |